- UEFI模式下安装Redhat/CentOS 6.x或7.x系统时加载raid卡驱动教程
- 安装Redhat/CentOS系统时提示Unsupported Hardware Detected(硬件不支持)
- 安装Redhat/CentOS 6.5时选择了freeipmi相关软件包,可能导致服务器不定时重启。
- UEFI模式下安装Redhat/CentOS 6.x或7.x系统时如果选择了tboot软件包,系统装完无法启动。
- SATA硬盘直连主板情况下安装Linux系统时,硬盘被识别为/dev/mapper/ddf1而不是/dev/sdX问题。
- RAID卡和HBA卡共存时,RHEL/CentOS 6.x系统启动时发生盘符漂移问题。
- Redhat/CentOS 6.3系统进入图形界面死机问题
- Redhat/CentOS 6.x系统下报错kernel:do_IRQ: x.x No irq handler for vector (irq -1)
- Redhat部分版本连续运行208天可能触发panic或自动重启
- Redhat/CentOS系统版本与内核版本对应关系
- Linux操作系统使用scp拷贝文件速度慢问题
- Linux系统下CPU、内存识别不全问题
- Linux系统装完以后网卡无法使用,灯不亮问题。
UEFI模式下安装Redhat/CentOS 6.x或7.x系统时加载raid卡驱动教程
问题描述
UEFI模式下安装Redhat 6.x/7.x系统时,和信息技术网上系统安装教程中的leagcy模式加载驱动方式不同。
问题原因
legacy模式,和UEFI模式加载阵列卡驱动有所不同。
解决方案
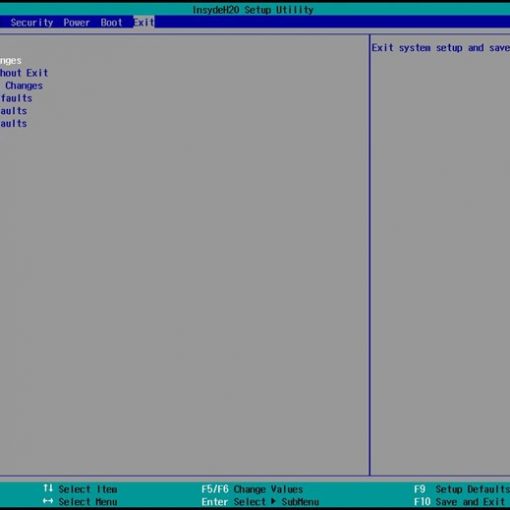
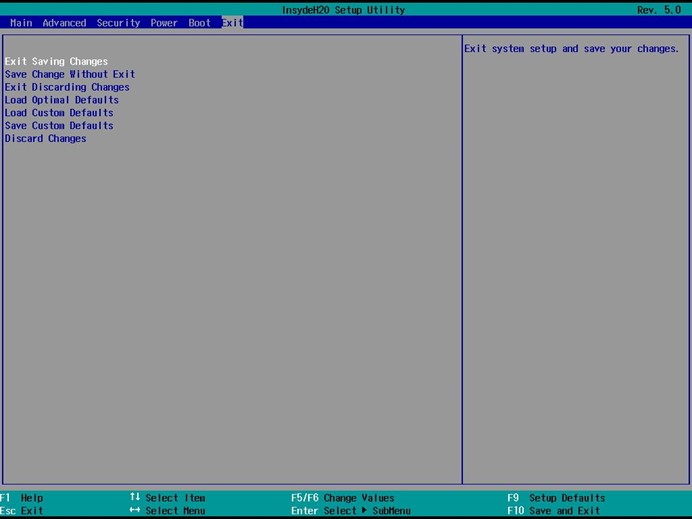
如果安装中确认需要加载阵列卡raid卡驱动,
进入GRUB菜单,移至”Install Red Hat Enterprise Linux 7.X”一行上按”E”键编辑启动参数。
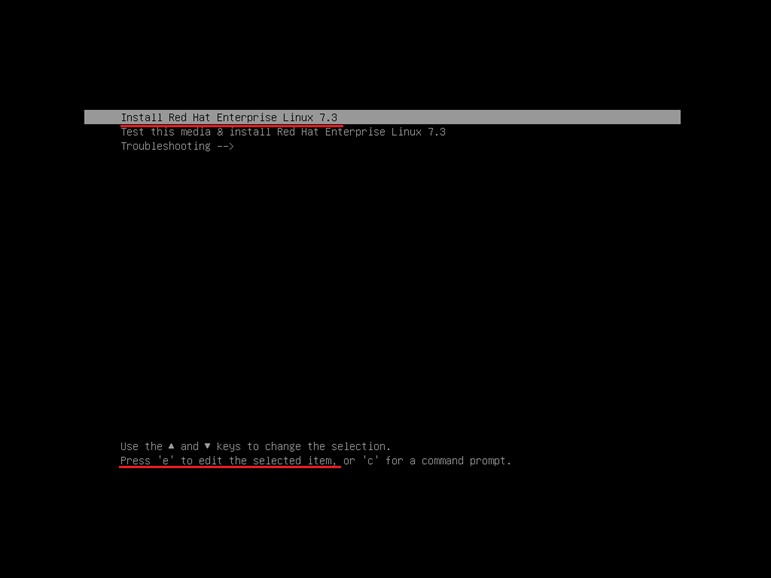
在linuxuefi 这行”quiet”前输入(空格)”dd”,然后按”Ctrl+X”组合键。

找到驱动所在的U盘,如”2) sda1″,输入数字”2″。
注意:如果没有识别到设备,需要先输入字母”R”刷新一次。剩余步骤和浪潮信息技术网一样。
安装Redhat/CentOS系统时提示Unsupported Hardware Detected(硬件不支持)
问题描述
在安装在Redhat/CentOS系统时,有时会报错如下信息:Unsupported Hardware Detected,This hardware(or a combination thereof) is not supported by RedHat. For more information on supported hardware, please refer to http://www.redhat.com/hardware
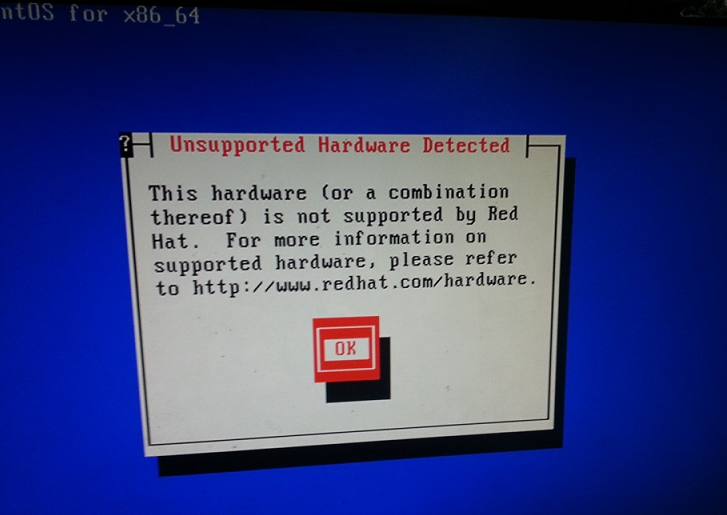
问题原因
Redhat/CentOS系统对于不同类型的CPU有不同的兼容性要求。
RedHat官方说明:https://access.redhat.com/support/policy/intel
例如:
Intel IvyBridge系列CPU E5-26xx/46xx/88xx V2需要6.4/7.0及以上版本才能支持;
Intel Haswell系列CPU E5-26xx/46xx V3需要6.5/7.0及以上版本才能支持;
Intel Haswell系列CPU E5-88xx V3需要6.6/7.1及以上版本才能支持;
Intel Broadwell系列CPU E5-26xx/46xx/88xx V4需要6.7/7.2及以上版本才能支持。
解决方案
忽略此提示继续安装即可,或者更换为上述要求的版本。当您使用PXE网络自动安装时,可在kickstart文件中添加unsupported_hardware参数(从RHEL/CentOS 6.4开始支持此参数),可以自动跳过此提示。可参考:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Installation_Guide/s1-kickstart2-options.html
安装Redhat/CentOS 6.5时选择了freeipmi相关软件包,可能导致服务器不定时重启。
问题描述
服务器不定时重启,收集日志查看,在意外关闭时间点之前十几分钟到二十几分钟内,会有bmc-watchdog报错,类似如下:
/usr/sbin/bmc-watchdog[xxxx]: fiid_obj_get:’present_countdown_value’: data not available
问题原因
此问题属于Redhat/CentOS 6.5系统Bug,官方说明:https://access.redhat.com/site/solutions/628963
初步分析是freeipmi无法正确重置watchdog timer,导致watchdog timer归零,从而触发BMC发送重启指令。
解决方案
方法一:卸载掉如下4个软件包

卸载时请使用rpm -e –nodeps命令,否则在卸载freeipmi-1.2.1-3.el6.x86_64时会提示conman-0.2.7-2.el6.x86_64和这个包有依赖关系。
方法二:升级freeipmi到1.2.1-6.el6_5或更新版本。
下载地址:http://rhn.redhat.com/errata/RHBA-2013-1795.html
升级指令:yum update freeipmi
升级完成需要启动服务,使用root用户登录,在/etc/modprobe.d/watchdog‐reboot‐workaround.conf文件中添加如下内容:
alias acpi:IPI000*:* ipmi_si
alias acpi:IPI000*:* ipmi_devintf
alias acpi:IPI000*:* ipmi_msghandler
然后执行以下命令:
# modprobe ipmi_devintf
# modprobe ipmi_msghandler
# modprobe ipmi_si
# service bmc‐watchdog condrestart
UEFI模式下安装Redhat/CentOS 6.x或7.x系统时如果选择了tboot软件包,系统装完无法启动。
问题描述
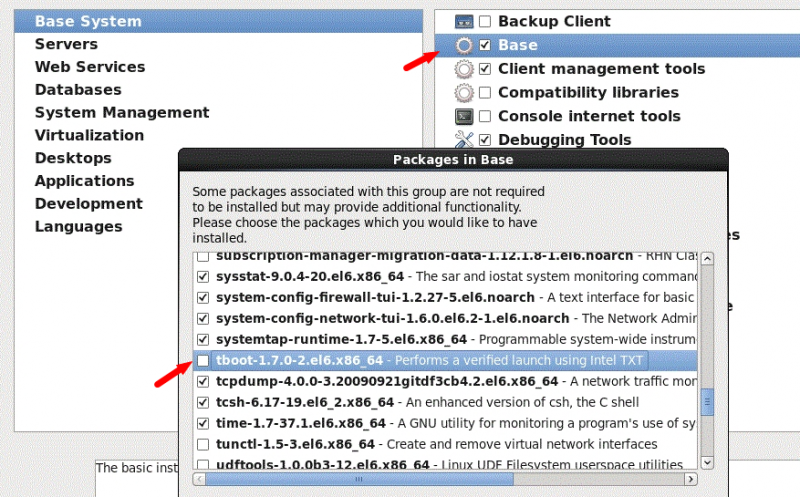
UEFI模式下安装Redhat 6.x/7.x系统时如果选择了tboot软件包,系统装完无法启动。提示:invalid magic number:0 Error 13:Invalid or unsupported executable format

问题原因
tboot在UEFI模式下不工作,导致系统无法启动。
解决方案
方法一:安装系统时请不要使用UEFI模式,而是Legacy传统方式。
方法二:如果一定要用UEFI模式安装系统,请不要选择tboot包。
SATA硬盘直连主板情况下安装Linux系统时,硬盘被识别为/dev/mapper/ddf1而不是/dev/sdX问题。
问题描述
安装系统时看不到本地磁盘,并且提示:”Disk sda,sdb contain BIOS RAID metadata, but are not part of any recognized BIOS RAID sets. Ignoring disks sda, sdb”,如下图:

问题原因
硬盘以前做过SATA RAID,且RAID信息没有完全删除,而Linux系统可以识别
到硬盘上的软RAID信息,并将硬盘标记为/dev/mapper/ddf1…的设备名,而不是/dev/sda这样的名称。
解决方案
在系统安装过程中,当发现硬盘被识别为/dev/mapper/ddf1….时,请先停止安装,参考《Intel SATA RAID配置文档》确认RAID已经删除,并且BIOS中SATA模式已改成AHCI。
如果以上操作无效,硬盘仍然被识别为/dev/mapper/ddf1….此时请按键盘上的Ctrl+Alt+F2进入后台命令行,执行以下操作。
1)查看当前软RAID情况:
# dmraid -r /dev/sda
/dev/sda: ddf1, “.ddf1_disks”, GROUP, ok, 976496964 sectors, data@ 0
软Raid配置文件会保存在当前目录下,或者当前目录的dmraid下。如果没有生成ddf1文件,再执行dmraid -r -E /dev/sda
2)执行以下命令查看软Raid配置文件:
# ls -l sda_ddf1.*
-rw——- 1 root root 6144 Jun 10 04:06 sda_ddf1.dat
-rw——- 1 root root 13 Jun 10 04:06 sda_ddf1.offset
-rw——- 1 root root 10 Jun 10 04:06 sda_ddf1.size
3)清除Raid信息:
# dd if=/dev/zero of=/dev/sda seek=`cat sda_ddf1.offset` bs=1 count=6144 (count为sda_ddf1.dat文件的大小)
6144+0 records in
6144+0 records out
6144 bytes (6.1 kB) copied, 0.0217024 seconds, 283 kB/s
# dmraid -r /dev/sda No RAID disks and with names: “/dev/sda”——>阵列信息被清除。
如果以上操作依然无效,或者始终不能生成软RAID配置文件,则无法使用本方法清除RAID,需要将硬盘拿到普通PC上进行低级格式化处理,低格完成即可正常使用。
RAID卡和HBA卡共存时,RHEL/CentOS 6.x系统启动时发生盘符漂移问题。
问题描述:
在RHEL 6中安装HBA卡并映射磁盘后,出现盘符漂移情况。比如原来系统盘所在的盘符为/dev/sda,映射磁盘并重启系统后,系统盘符变为最后一个,如
/dev/sdf。
问题原因:
Linux内核中,SCSI硬盘盘符的分配与驱动扫描到的硬盘先后顺序有关,即第一块扫描到的硬盘盘符为/dev/sda,第二块盘符为/dev/sdb … 依次类推。
一般情况下,驱动扫描到的硬盘顺序与不同类型SAS/RAID控制器驱动加载顺序有关。如先加载Raid卡驱动,则该RAID控制器下的硬盘会首先分配盘符,即/dev/sda所对应的硬盘在该RAID控制器下。若先加载HBA卡驱动,则HBA卡映射过来存储卷会首先得到盘符,此时/dev/sda指的是HBA卡下面的存储。
因此,发生盘符漂移的原因是HBA/RAID控制器的驱动加载顺序发生了变化。而加载顺序是udev机制配置文件决定的。
解决方案:
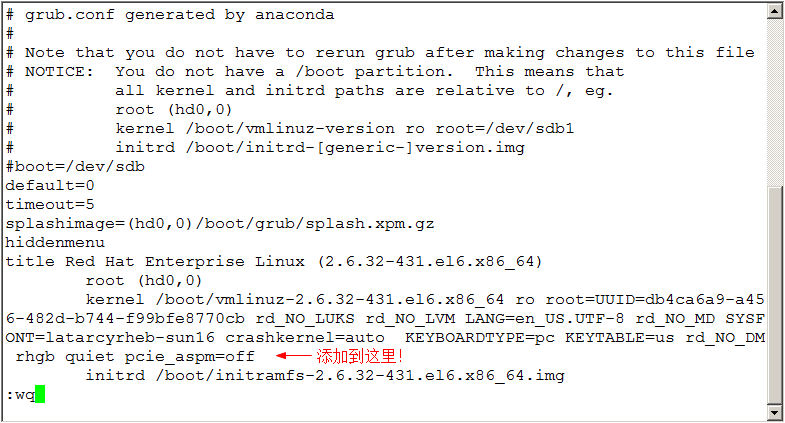
在通过udev机制加载驱动前,内核先加载initramfs文件中01parse-kernel.sh脚本中的rdloaddriver参数。因此,我们只需在发生盘符漂移的机器的grub.conf文件中指定驱动的加载顺序即可。
例如先加载megaraid_sas驱动(LSI Raid卡驱动名字),再加载qla2xxx驱动(Qlogic HBA卡驱动名字),可以在grub.conf文件中kernel一行最后添加参数如下:
title Red Hat Enterprise Linux (2.6.32-358.el6.x86_64)
root (hd0,0)
kernel /vmlinuz-2.6.32-358.el6.x86_64 ro root=UUID=e3469fb3-54b0-4207-9aab-7ead38ea4f9a rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=128M KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet rdloaddriver=megaraid_sas rdloaddriver=qla2xxx
initrd /mpp-2.6.32-358.el6.x86_64.img
如果是Adaptec Raid卡,驱动名称是aacraid
如果是Emulex HBA卡,驱动名称是lpfc
如果系统下安装了RDAC多路径软件,HBA卡驱动要选择mppUpper
经验证,实际上只需添加Raid卡驱动的参数就行了。
Redhat/CentOS 6.3系统进入图形界面死机问题
问题描述:
RHEL6.3系统启动图形界面后,鼠标操作延迟,并且很快出现死机。如果进入命令行模式则正常。
问题原因:
此问题产生跟内核有一定的关系,6.3的内核与图形界面及部分设备的驱动存在兼容性的错误。这个错误的产生与 intel的iommu的功能有关。
查看系统日志时,会有如下报错:
Sep 21 13:32:21 localhost kernel: pcieport 0000:00:03.0: AER: Corrected error received: id=0018
Sep 21 13:32:21 localhost kernel: pcieport 0000:00:03.0: PCIe Bus Error: severity=Corrected, type=Physical Layer, id=0018(Receiver ID)
Sep 21 13:32:21 localhost kernel: pcieport 0000:00:03.0: device [8086:340a] error status/mask=00000001/00002000
Sep 21 13:32:21 localhost kernel: pcieport 0000:00:03.0: [ 0] Receiver Error (First)
解决方案:
先启动命令行界面,然后编辑/etc/grub.conf文件,可以看到里面有 intel_iommu=on内核选项,不能正常启动原因就在这里。将on更改成off,保存重启生效,可以正常进入图形化界面。
Redhat/CentOS 6.x系统下报错kernel:do_IRQ: x.x No irq handler for vector (irq -1)
问题描述:

问题原因:
驱动卸载函数中,忘记调用pci_disable_device()函数来关闭PCI设备,或者关闭PCI设备失败。导致request_irq()中申请到的中断向量vector与该PCI设备对应关系,可能不会被解除。于是当再次加载该PCI设备驱动后,PCI设备发出中断,内核仍然会以旧的中断向量vector来解析中断号。但此时vector是第一次驱动加载时,内核分配的vector;而驱动卸载调用free_irq()将vector与物理中断号irq对应关系解除。于是解析到的irq为0xffffffff。
解决方案:
编辑/etc/grub.conf文件,在kernel一行最后添加 pcie_aspm=off,保存重启生效。
Redhat部分版本连续运行208天可能触发panic或自动重启
问题描述
操作系统长时间运行达到208.5天后,会因为sched_clock()计数器溢出而导致内核崩溃kernel panic。如果操作系统配置了kdump,到时候会触发kdump机制而自动重启。
而且某些进程还会在日志中产生类似如下报错:
BUG: soft lockup – CPU#N stuck for 4278190091s!
问题原因
该问题的产生与操作系统Time Stamp Counter (TSC) clock source有关,采用TSC时钟源的系统会触发此Bug。
使用下面的命令可以查看当前系统所使用的时钟源:
cat /sys/devices/system/clocksource/clocksource0/current_clocksource
Redhat官方描述如下:
- An insufficiently designed calculation in the CPU accelerator in the previous kernel caused an arithmetic overflow in thesched_clock()function
- This overflow led to a kernel panic or any other unpredictable trouble on the systems using the TSC clock source
- This problem will occur only when system uptime reaches or exceeds 208.5 days
- This update corrects the aforementioned calculation so that this arithmetic overflow and kernel panic can no longer occur under these circumstances
- On RHEL5, this problem is a timing issue and is very unlikely to be encountered.
- Switching to another clocksource is usually not a workaroundfor most workloads
- The TSC is a fast access clock, whereas the HPET and PMTimer are both slow access clocks
- Using notsc would be a significant performance hit
- In RHEL5, the affected sched_clock()uses the TSC regardless of clock source selection.
- Also, in some situation, the system may hit this issue even if you set notsc to current_clocksource.
解决方案
此问题属于Redhat系统Bug,需要联系Redhat获取内核更新(只有购买了正版授权才能获取更新资料),升级内核解决。
Redhat/CentOS系统版本与内核版本对应关系
Red Hat Enterprise Linux 5 (Tikanga), 2007-03-14. kernel 2.6.18-8
5.1, also termed Update 1, 2007-11-07 (kernel 2.6.18-53)
5.2, also termed Update 2, 2008-05-21 (kernel 2.6.18-92)
5.3, also termed Update 3, 2009-01-20 (kernel 2.6.18-128)
5.4, also termed Update 4, 2009-09-02 (kernel 2.6.18-164)
5.5, also termed Update 5, 2010-03-30 (kernel 2.6.18-194)
5.6, also termed Update 6, 2011-01-13 (kernel 2.6.18-238)
5.7, also termed Update 7, 2011-07-21 (kernel 2.6.18-274)
5.8, also termed Update 8, 2012-02-20 (kernel 2.6.18-308)
Red Hat Enterprise Linux 6 (Santiago), 2010-11-10. kernel 2.6.32-71
6.1 also termed Update 1, 2011-05-19 (kernel 2.6.32-131)
6.2 also termed Update 2, 2011-12-06 (kernel 2.6.32-220)
6.3 also termed Update 3, 2012-06-20 (kernel 2.6.32-279)
6.4, also termed Update 4, 2013-02-21(kernel 2.6.32-358)
6.5, also termed Update 5, 2013-11-21(kernel 2.6.32-431)
6.6, also termed Update 6, 2014-10-13(kernel 2.6.32-504)
6.7, also termed Update 7, 2015-07-22(kernel 2.6.32-573)
6.8, also termed Update 8, 2016-05-10(kernel 2.6.32-642)
Red Hat Enterprise Linux 7 (Maipo), 2014-06-10. kernel 3.10
| Release | General Availability Date | redhat-release | Kernel Version |
| RHEL 7.0 Beta | 2013-12-11 | – | 3.10.0-54.0.1 |
| RHEL 7.0 GA | 2014-06-09 | – | 3.10.0-123 |
| RHEL 7.1 | 2015-03-05 | 2015-03-05 | 3.10.0-229 |
| RHEL 7.2 | 2015-11-19 | 2015-11-19 | 3.10.0-327 |
Linux操作系统使用scp拷贝文件速度慢问题
问题描述
Linux系统下使用scp命令在服务器间网络拷贝文件速度慢,例如千兆网络最高可能只有30-40MB/S,远小于网络带宽和磁盘性能。
问题原因
scp是secure copy的简写,用于在Linux下进行远程拷贝文件的命令。scp在拷贝文件前需要先加密,而加密需要消耗较多CPU资源,并且scp命令是单线程的,也影响了数据传输速度。
解决方案
更改加密方式:scp -c arcfour,实测在万兆网络环境下速度可以达到130MB/S。
注意:请不要使用scp拷贝文件方式测试网络带宽。
Linux系统下CPU、内存识别不全问题
问题描述
BIOS下面CPU、内存识别正常(这是前提),但系统下用cat /proc/cpuinfo和free命令查看CPU和内存比实际要少。
问题原因
常见原因有如下两个
1、/boot/grub/menu.lst文件中有nosmp参数,将smp功能禁用,所以只能识别到1个cpu的1个核心。
2、安装了虚拟化Xen内核,此时用cat /proc/cpuinfo和free命令看到的只是分配给主机的资源,其他资源是系统保留给虚拟机使用的。
解决方案
1)可以查看dmesg日志,检查有无nosmp参数,如果有,如下:![]()
2)可以修改/boot/grub/menu.lst,将nosmp删除就可以识别cpu正常。使用uname -a查看当前系统是否是xen内核,如果是,如下:
Linux version 2.6.18-238.12.1.el5xen
应当使用xm info查看所有的cpu、内存资源。
Linux系统装完以后网卡无法使用,灯不亮问题。
问题描述
Linux系统装完以后网卡无法使用,ifconfig看不到网卡信息,插上网线网卡灯不亮。
问题原因
在安装Linux系统时如果没有配置网卡,则装完以后网卡默认不激活。
解决方案
修改网卡配置文件,激活网卡并重启网络服务。
配置文件位于/etc/sysconfig/network-scripts/目录下,例如ifcfg-eth0,内容如下:
DEVICE=eth0
ONBOOT=yes
HWADDR=00:30:48:7f:b5:ca
TYPE=Ethernet
NETMASK=255.255.255.0
IPADDR=192.168.1.100
GATEWAY=192.168.1.254
BOOTPROTO=static
请将标红部分ONBOOT参数改成yes,然后执行service network restart命令重启网络服务。



{kind=link}
{kind=link}